En analyse de données, il est parfois très utile de constituer des groupes homogènes d’observations c’est a dire d’individus partageant des similarités. La méthode des Kmeans permet de faire cela. Le présent billet de blog va introduire la méthode en utilisant R.
Le partitionnement (clustering) est une méthode d’apprentissage non supervisée qui vise à rassembler les observations similaires d’un jeu de données en des sous-groupes bien distincts les uns des autres. Cela est particulièrement utile pour le ciblage de clients, la définition de nouveau kit ou pack produit. Une méthode de clustering des plus utilisées est le kmeans (K-moyennes) qui vise à créer k groupes à partir de votre jeu de données. L’algorithme est assez simple et intuitif, je vous laisse une vidéo ici.
Dans ce tutoriel, nous allons apprendre comment implémenter la méthode des kmeans sur un jeu données notamment palmerpenguins.
Librairies utiles
L’algorithme des kmeans, est disponible dans le R de base via la fonction kmeans() . Nous aurons besoin du package tidyverse pour la manipulation des données et de palmerpenguins pour le jeu de données.
Attaching package: 'tidylog'
The following objects are masked from 'package:dplyr':
add_count, add_tally, anti_join, count, distinct, distinct_all,
distinct_at, distinct_if, filter, filter_all, filter_at, filter_if,
full_join, group_by, group_by_all, group_by_at, group_by_if,
inner_join, left_join, mutate, mutate_all, mutate_at, mutate_if,
relocate, rename, rename_all, rename_at, rename_if, rename_with,
right_join, sample_frac, sample_n, select, select_all, select_at,
select_if, semi_join, slice, slice_head, slice_max, slice_min,
slice_sample, slice_tail, summarise, summarise_all, summarise_at,
summarise_if, summarize, summarize_all, summarize_at, summarize_if,
tally, top_frac, top_n, transmute, transmute_all, transmute_at,
transmute_if, ungroup
The following objects are masked from 'package:tidyr':
drop_na, fill, gather, pivot_longer, pivot_wider, replace_na,
spread, uncount
The following object is masked from 'package:stats':
filter
library(palmerpenguins)
Préparation des données
La méthode des kmeans requiert uniquement des données numériques et ne tolère pas de données manquantes. En effet la similarité entre les observations est en fait une mesure de distance (par exemple euclidienne) entre elles. Plus la distance entre deux observations est petite, plus ces dernières sont similaires. Alors jetons regardons de près notre jeu de données
Le jeu de données penguins est constitué de 344 observations et 8 variables dont trois catégorielles et 5 numériques. La variable année bien que numérique n’est pas pertinente pour l’analyse. Nous les enlèverons pour la suite, pour cela nous utiliserons la fonction select_if() de dplyr . Les données manquantes seront supprimés dans notre cas avec la fonction drop_na()
Voilà qui est fait, notre je de données est réduit à présent à quatres variables et 342 observations.
Lorsque les données sont exprimées dans des unités différentes comme ici grammes et millimètres, les variables ne sont pas intercomparables. Pour résoudre cela, les données sont parfois centrées et réduites. Nous pouvons faire cela avec la fonction scale().
Les données sont désormais sans unités, sur la même échelle et sont donc intercomparables.
Implémentation du kmeans
Maintenant nous allons implémenter la méthode du kmeans qui exige un nombre de cluster (groupe) . Bien entendu cela suppose que l’on a déja une idée du nombre de cluster que l’on souhaite avoir. Nous verrons par la suite qu’il existe des techniques basées sur la variance intra et inter-groupes qui nous permettrons d’avoir une idée du nombre optimal de cluster suivant la structure de nos données. Ce nombre tendra a minimisé la variance intra-groupe et à maximiser la variance inter-groupe. Voyons donc de près comment tout ça marche.
La fonction kmeans() est relativement simple à utiliser et voici les arguments à fournir au minimum.
kmeans(x, centers =3, iter.max =20, nstart =10)
Note
x : matrice numérique, dataframe ou tibble numérique ou simplement un vecteur numérique.
centers : le nombre de clusters (k), alors un ensemble aléatoire de lignes (distinctes) dans x est choisi comme centres initiaux.
iter.max : nombre maximal d’itérations autorisées. La valeur par défaut est 10.
nstart : le nombre de partitions de départ aléatoires. Choisir nstart > 1 est recommandé.
Les autres arguments supposent des analyses poussées qui ne sont pas abordées dans cet tutoriel introductif. vous aurez à la fin une liste de documents à consulter pour approfondir le sujet.
Nombre de clusters prédéfinis
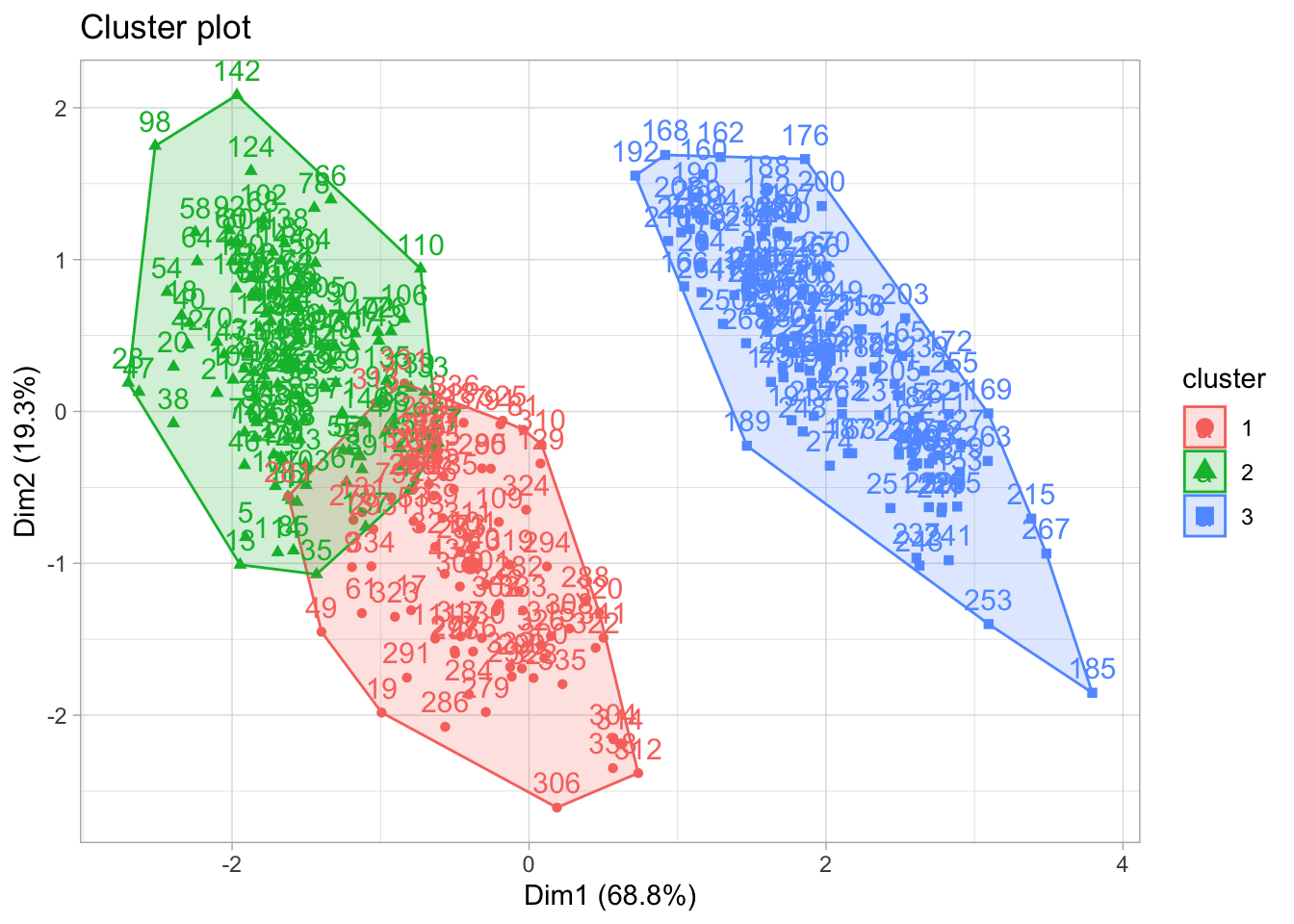
Comme il faut bien fournir un nombre de cluster, partons sur la base que pour des besoins pratiques nous voulons regroupé nos penguins en trois groupes plutôt homogène sur la base des quatre variables. La sélection des centres de classes se faisant de façon aléatoires, pour garantir la reproductibilité des analyses, nous devons fixé les résultats qui seront fournis par le RNG (random number generator) à travers la fonction set.seed()
# les informations sur les variancesglance(km_res)
# A tibble: 1 × 4
totss tot.withinss betweenss iter
<dbl> <dbl> <dbl> <int>
1 1364 378. 986. 3
Nous avons choisi 20 itérations pour le choix des centres. Le meilleur partitionnement est obtenu au numéro iter.
Aussi il est particulièrement utile de joindre au jeu de données penguins_num une variable .cluster qui va identifier à quel cluster appartient une observation donnée.
select_if: dropped 3 variables (species, island, sex)
drop_na: removed 2 rows (1%), 342 rows remaining
Joining, by = c("bill_length_mm", "bill_depth_mm", "flipper_length_mm",
"body_mass_g")
left_join: added one column (.cluster)
> rows only in x 2
> rows only in y ( 0)
> matched rows 342
> =====
> rows total 344
drop_na: removed 11 rows (3%), 333 rows remaining
Comme annoncé plus tôt, comment s’assurer du bon choix de k pour garantir le meilleur clustering possible de notre jeu de données ?
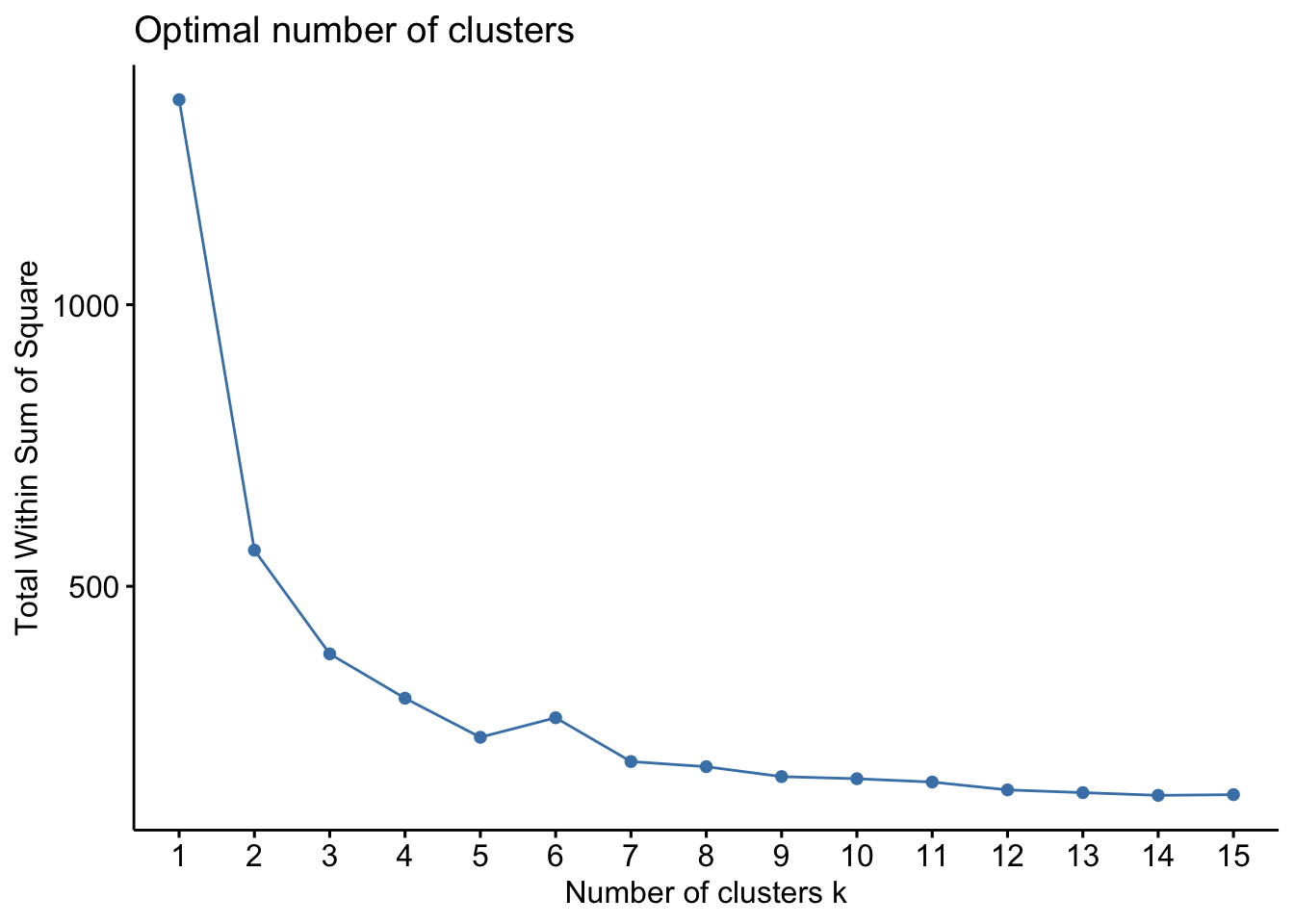
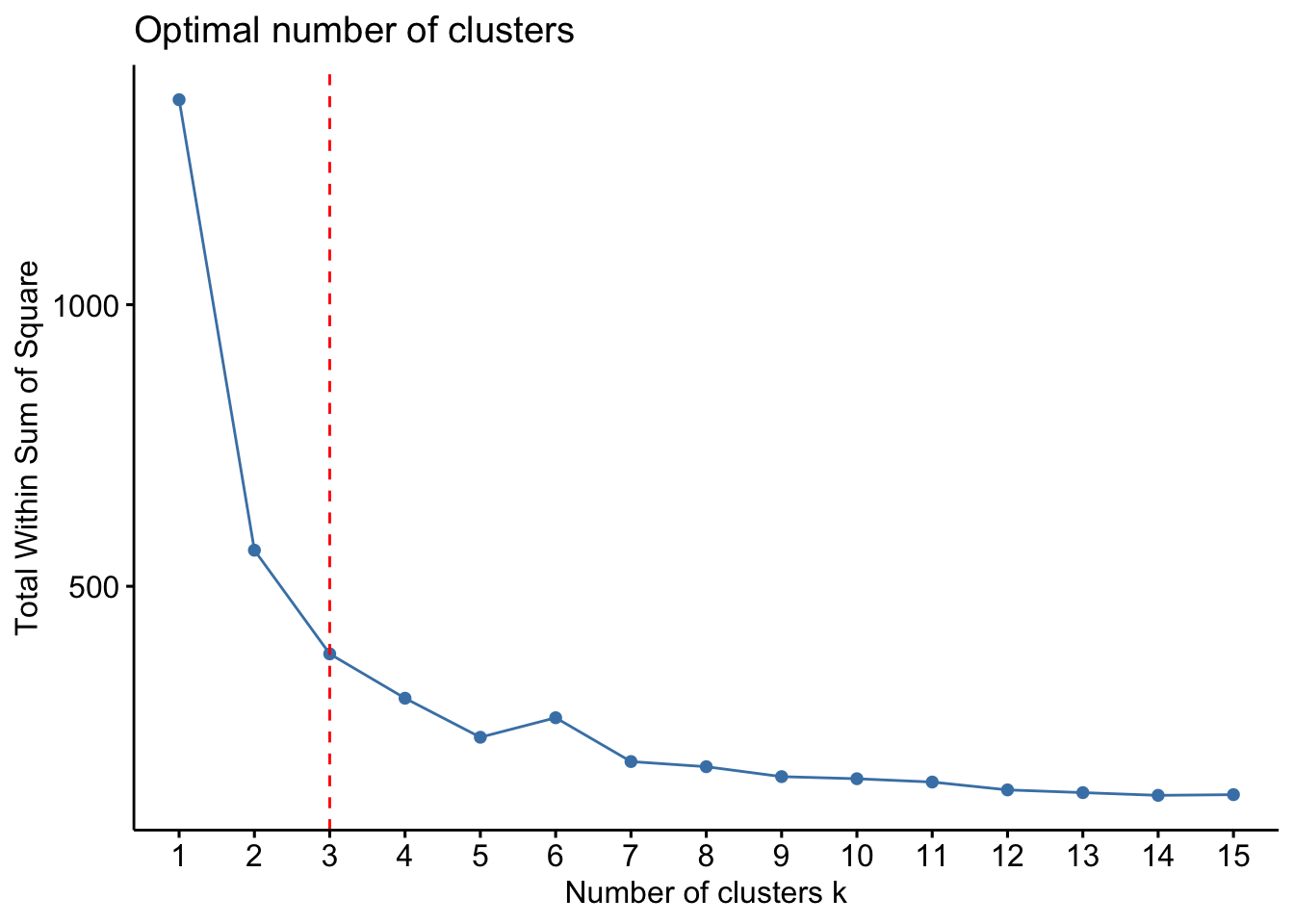
Plusieurs approches existent, mais la plus simple consiste à réaliser le kmeans avec des valeurs différentes de k afin de voir comment évolue la variance intra-groupe. En abcisse on aura le nombre de clusters et en ordonnées la variance intra-groupe. Le nombre optimale de cluster se situe la ou se trouve le coude. Vous l’aurez compris c’est une méthode visuelle : la méthode du coude (elbow). La fonction fviz_nbclust() du package factoextra permet celà.
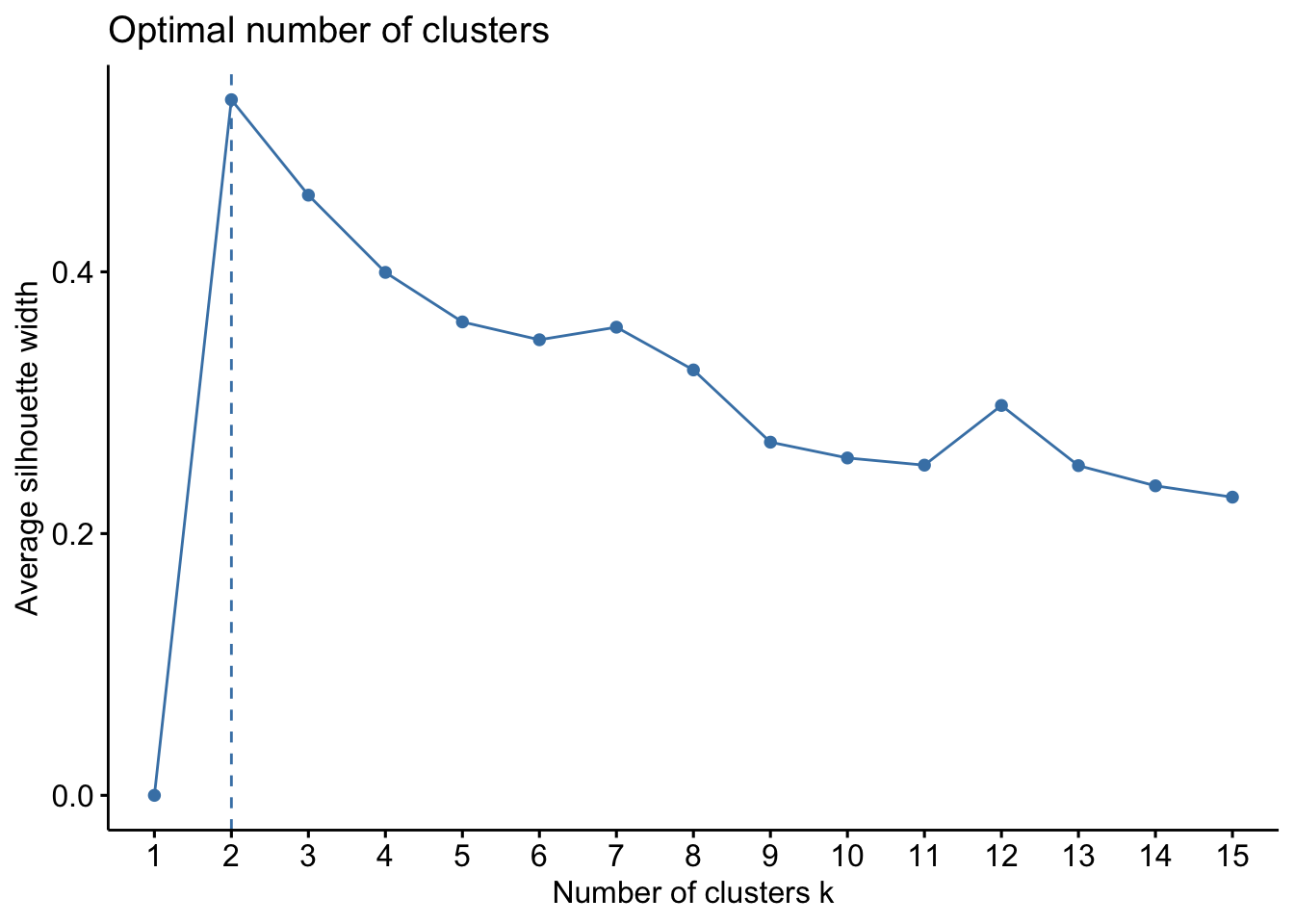
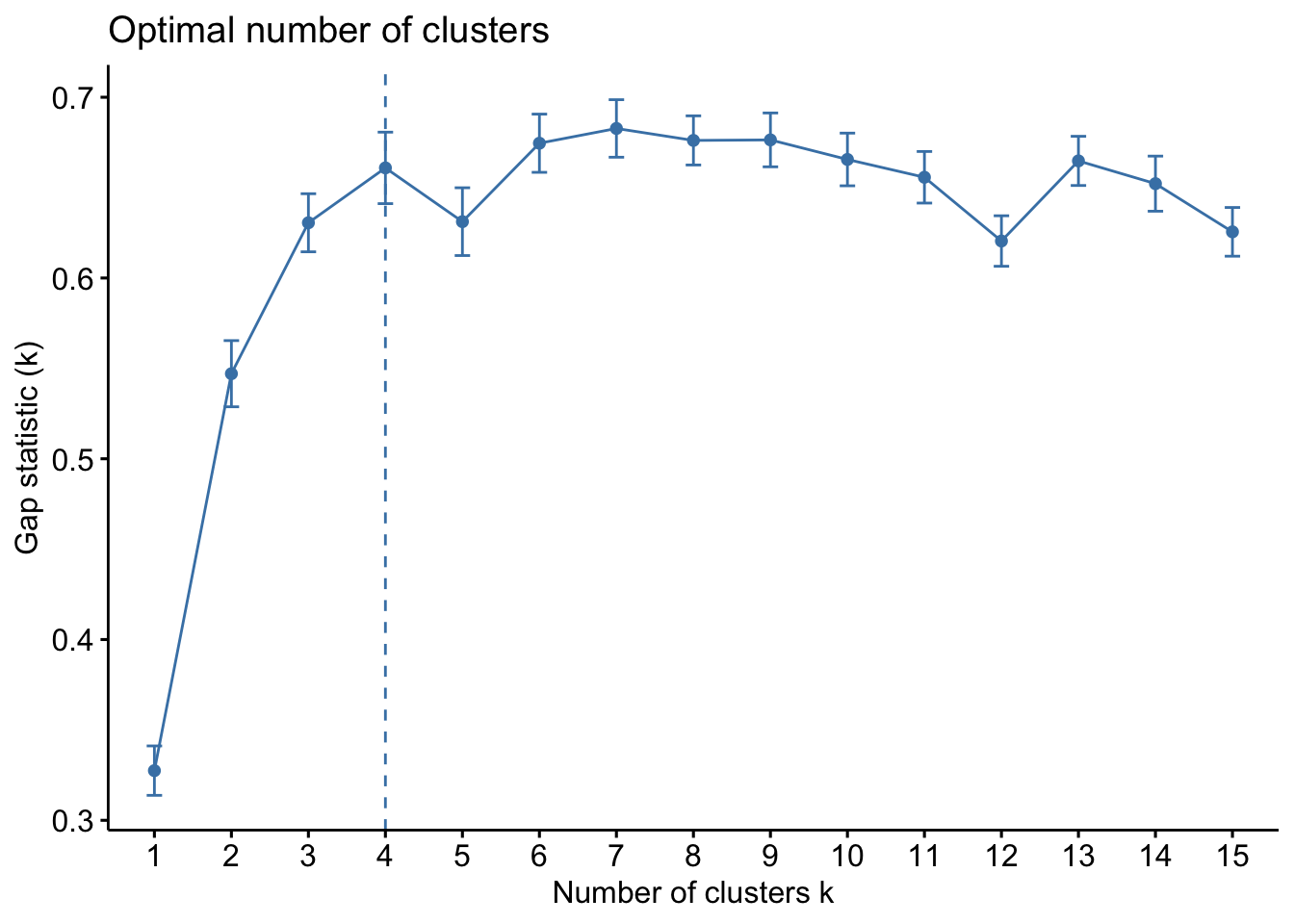
D’autres méthodes comme “silhouette” ou “gap_statistic sont implémentés pour estimer le nombre optimal de cluster k. Pour en savoir plus sur ces méthodes et bien d’autres consulter cet excellent article.
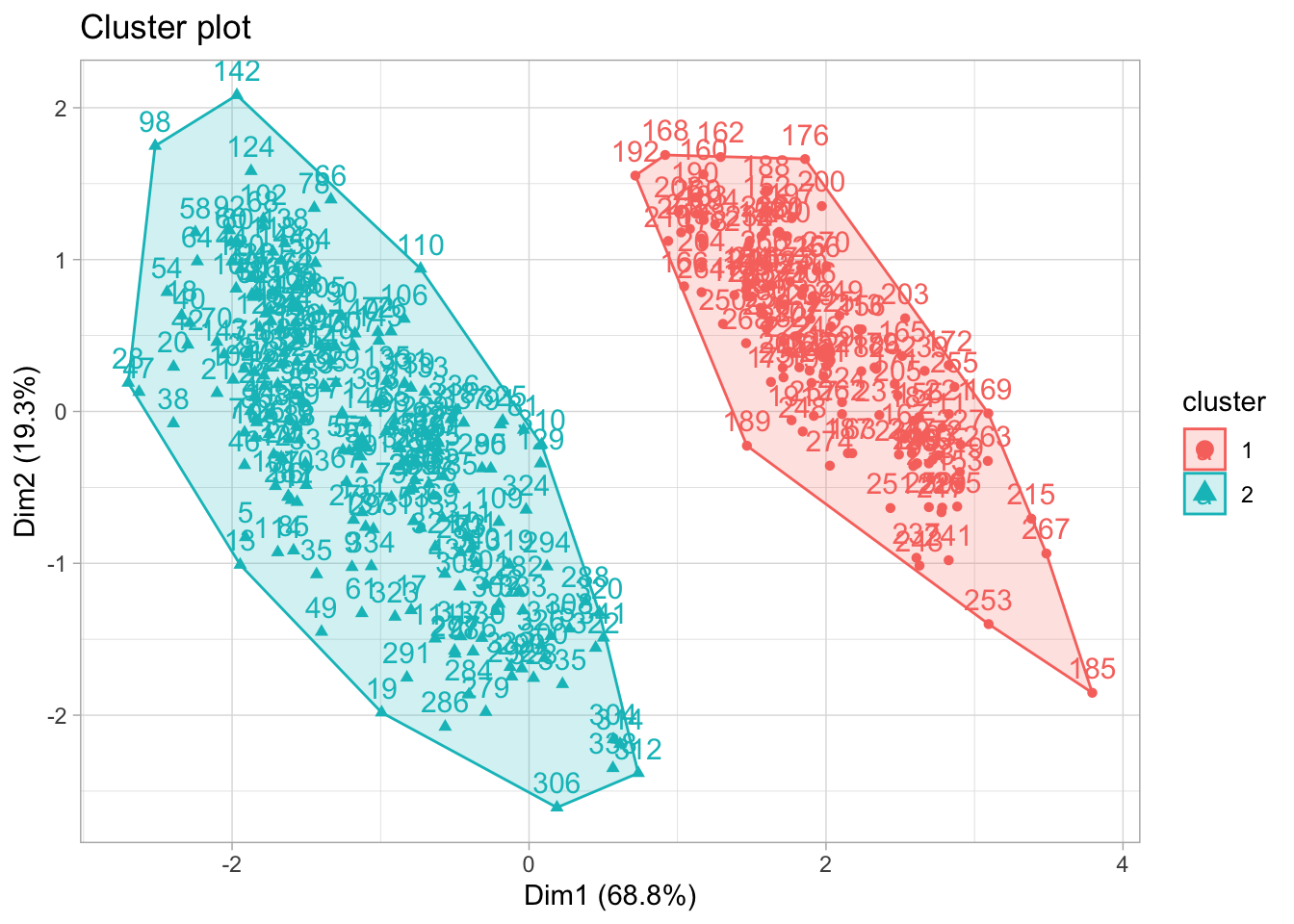
La méthode “silhouette” nous suggère deux clusters.
De toute les façons ce sont des indications pour le clustering. On pourra par aggression visuelle s’assurer de la bonne partition des données. Nous allons donc entamer un nouveau point à savoir la visualisation des clusters.
Visualisation des clusters
Jusque là, nous avons manipuler le résultat de notre clustering de façon numérique. Il serait bon de visualiser le résultat. A cet effet, la fonction fviz_cluster() du package factoextra nous permet de visualiser les données avec le moins de code possible.
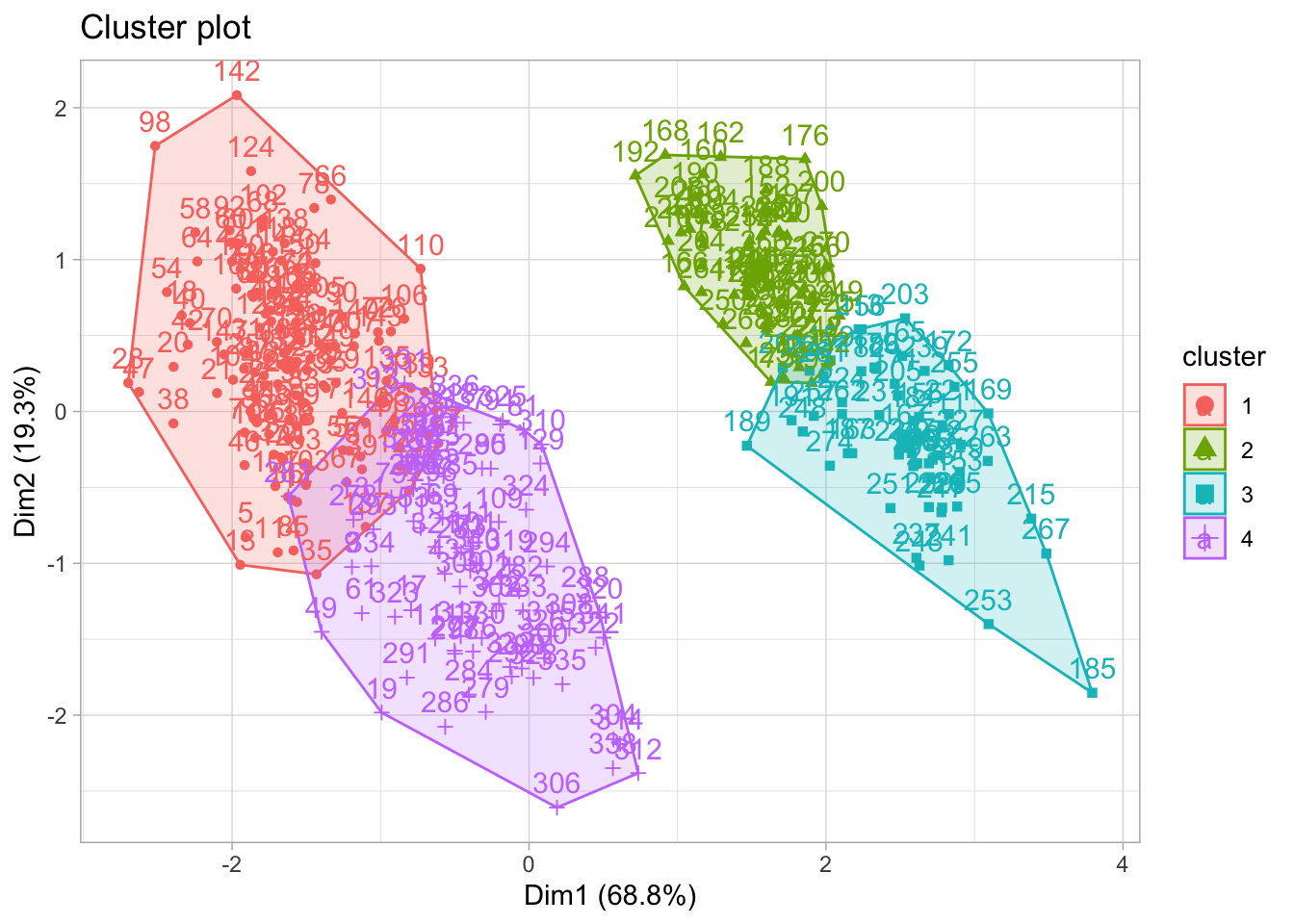
Par agression visuelle aussi, les données semblent ne pas être bien partitionnées. Les graphiques laissent voir en réalités deux clusters comme nous le proposait la méthode “silhouette”. Vous l’aurez compris, il ne s’agit pas juste d’exécuter du code et de prendre les résultats pour de l’argent comptant.
Voilà qui est assez interréssant. Les données se regroupent en mieux en deux clusters.
Conclusion
Nous voilà à la fin de ce court tutoriel pour vous introduire au clustering avec R. Les notions couvertent ici sont loin de faire le tour de l’état d’art sur la question. Pour approfondir le sujet je vous recommande les contenus ci après :